【第2回】"誰でも気軽に"⾔語データを解析できる テキストマイニング
企業活動の意思決定に役⽴つ情報を⼊⼿するためには、データを「うまく」収集し分析することが求められます。
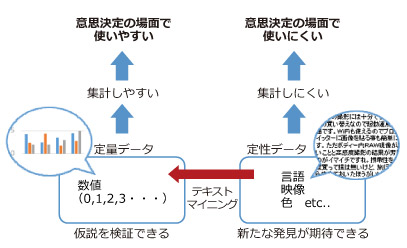
データには、数値の形式で⼊⼿する定量データと、⾔語、映像、⾊彩等の数値以外の形式で⼊⼿する定性データの2種類があります。
例えば、企業が製品企画のために⾏うアンケートでは、施験者が⽴てた仮説のもとに、段階評価等によって被験者に評価を求め、結果を集計して意思決定の材料として⽤います。このようなデータの形式が定量データで、意思決定において結果が「使いやすい」形式と⾔えます。
⼀⽅、アンケートでは上記に加えて⾃由回答形式の設問が⽤いられることがあります。これは、仮説を検証するというより、未知なる新しい発⾒をしたい場合に⽤いられます。このようなデータの形式は⾔語によって記述する定性データです。
この形式は、個々の被験者に対して⼀対⼀でアプローチしていくような場合には有益ですが、集計して定量化するのが⼤変なため、総合的な意思決定の場においては、結果が「使いにくい」形式と⾔えます。
⾔語データを無理に集計しようとすると、意味の解釈や分類に分析者の主観が⼊り、判断の材料として使いにくくなるためです。そのため、集計の労⼒を割いた割には参考程度にしか使われず、せっかくのデータを無駄にしてしまう状況が多く⾒られます。
<関連資料のご案内>
製品企画段階の耐久消費財において、製品の売れる要因を発⾒し、製品企画の意思決定に活⽤できる情報収集・分析をテキストマイニングと統計的⼿法を⽤いてその有効性を検証し、資料にまとめました。
データには、数値の形式で⼊⼿する定量データと、⾔語、映像、⾊彩等の数値以外の形式で⼊⼿する定性データの2種類があります。
例えば、企業が製品企画のために⾏うアンケートでは、施験者が⽴てた仮説のもとに、段階評価等によって被験者に評価を求め、結果を集計して意思決定の材料として⽤います。このようなデータの形式が定量データで、意思決定において結果が「使いやすい」形式と⾔えます。
⼀⽅、アンケートでは上記に加えて⾃由回答形式の設問が⽤いられることがあります。これは、仮説を検証するというより、未知なる新しい発⾒をしたい場合に⽤いられます。このようなデータの形式は⾔語によって記述する定性データです。
この形式は、個々の被験者に対して⼀対⼀でアプローチしていくような場合には有益ですが、集計して定量化するのが⼤変なため、総合的な意思決定の場においては、結果が「使いにくい」形式と⾔えます。
⾔語データを無理に集計しようとすると、意味の解釈や分類に分析者の主観が⼊り、判断の材料として使いにくくなるためです。そのため、集計の労⼒を割いた割には参考程度にしか使われず、せっかくのデータを無駄にしてしまう状況が多く⾒られます。
⾔語データにはこういった集計しにくいという⽋点はあるものの、定量的な評価結果では気づかない、新しい発⾒を期待できるという⼤きなメリットがあります。
近年、この⽋点を解決するために、⾔語データをコンピュータで単語レベルに分割し、解析した結果から意味を抽出しょうと
するテキストマイニングが誕⽣しました。しかし、テキストマイニングに対して次のようなイメージをもたれる⽅が多いようです。
近年、この⽋点を解決するために、⾔語データをコンピュータで単語レベルに分割し、解析した結果から意味を抽出しょうと
するテキストマイニングが誕⽣しました。しかし、テキストマイニングに対して次のようなイメージをもたれる⽅が多いようです。
- ⾼価な専門ソフトウェアを必要とする。
- ⼤規模な情報量が必要でデータの収集が⼤変。
- ⼤規模な業務改善等で使われるようだが、⾃分の業務で使うイメージが浮かばない。
いずれも、少し前まではこのような状況でした。
しかし、近頃はテキストマイニングを実施しやすくする次のような環境が整っています。
しかし、近頃はテキストマイニングを実施しやすくする次のような環境が整っています。
- フリーウェアのテキストマイニングツールが公開されている。
- ⾝近に扱えるテキスト形式のデータ量が増加している。
(Web上のSNS、企業内の⽂書データ等) - テキストマイニングの結果を有効に活⽤できる統計的⼿法が存在する。
つまり、今は“誰もが気軽に”テキストマイニングを⾏える時代になりました。ぜひこの機会に⾔語
データ解析スキルを⾝につけてみませんか?
学校法⼈産業能率⼤学 総合研究所 経営管理研究所 研究員 福岡 宣⾏
※所属・肩書きは掲載当時のものです。
今回の内容に関連する資料はこちらからダウンロードできます
製品企画段階の耐久消費財において、製品の売れる要因を発⾒し、製品企画の意思決定に活⽤できる情報収集・分析をテキストマイニングと統計的⼿法を⽤いてその有効性を検証し、資料にまとめました。