【第3回】⼈材開発活動に必要なテストの作成⽅法と考え⽅・すすめ⽅
第3回 項目分析
ところで、解答の選択肢が与えられている客観式の試験問題や性格検査のような質問項目の場合は、仮に問題がよく分からなくても解答できてしまうという⽋点があります。試験問題であればたまたま選んだ選択肢が正解の場合がありうるわけです。このような項目が多いとしたら、そもそもそのテストの結果を信⽤してよいかどうかわからなくなってしまいます。
そこで、今回はより良いテストを作成していくために必要な、「項目分析」について解説します。
1.測定について
特性への各項目の貢献⼒を調べることを項目分析(item analysis)と呼びます。
現在、項目分析を⾏うための⽅法はたくさん提案されていますが、ここでは⼤きく3つの⽅法を紹介しようと思います。
(1) 項目特性図による分析
(2) 通過率による分析
(3) 識別⼒による分析
特に(1)項目特性図による分析⽅法は非常に強⼒で、専門家の間では項目分析の決定版だと⾔われています。項目特性図を描くためには、特に⾼度な統計解析ソフトも必要ではなく、多くの企業で採⽤されているビジネス⽤の表計算ソフトさえあれば可能ですので、ぜひ実際に作成してみて下さい。
さて、それではまず、項目分析を始めるための準備をしていきましょう。
テスト実施後、⼿元には多くの答案、またはアンケート⽤紙が集まることになります。このとき、最初にすることはテスト結果のデータ化です。テスト結果を表計算ソフトなどに⼊⼒することはテストの分析を⾏う第⼀歩になります。
例えば、能⼒テストを実施した場合、明確な正答と誤答がありますので、正答を1、誤答を0として⼊⼒します。ただし、1~4までの複数選択肢から正解を選 ぶような多肢選択問題の場合は、以下のようにそのまま⼊⼒しておきます。また、4件法などで実施されるようなアンケート調査の場合も同様です。
このようなデータを⽣データ(raw data)と呼びます。
さて、それではまず、項目分析を始めるための準備をしていきましょう。
テスト実施後、⼿元には多くの答案、またはアンケート⽤紙が集まることになります。このとき、最初にすることはテスト結果のデータ化です。テスト結果を表計算ソフトなどに⼊⼒することはテストの分析を⾏う第⼀歩になります。
例えば、能⼒テストを実施した場合、明確な正答と誤答がありますので、正答を1、誤答を0として⼊⼒します。ただし、1~4までの複数選択肢から正解を選 ぶような多肢選択問題の場合は、以下のようにそのまま⼊⼒しておきます。また、4件法などで実施されるようなアンケート調査の場合も同様です。
このようなデータを⽣データ(raw data)と呼びます。

2.項目特性図の作成⽅法
項目特性図は、横軸に測ろうとしている特性を、縦軸に確率を配して、項目反応の選択確率を選択肢ごとに結んだ折れ線グラフで表現されます。
⾔葉にすると難しいので、具体例として図1に⽰しておきます。質問項目⼀つにつきグラフを⼀つ作ります。
⾔葉にすると難しいので、具体例として図1に⽰しておきます。質問項目⼀つにつきグラフを⼀つ作ります。
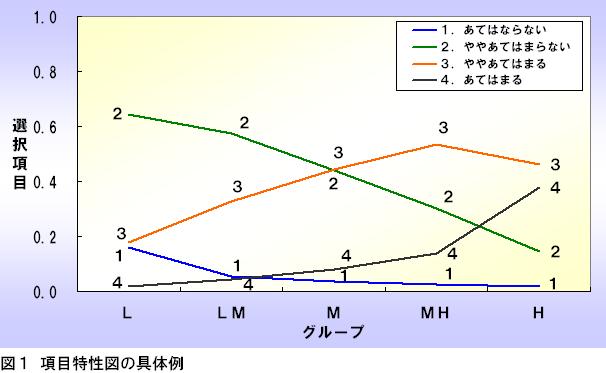
この図は、あるテストで使⽤された1番目の項目の項目特性図です。
このテストは各項目に対して、「あてはまらない」から「あてはまる」までを1~4の数値でコーディングされた4件法の性格検査です。
図の作成⽅法には様々な流儀がありますが、本コラムでは以下のような⼿順で作成する⽅法を紹介します。
このテストは各項目に対して、「あてはまらない」から「あてはまる」までを1~4の数値でコーディングされた4件法の性格検査です。
図の作成⽅法には様々な流儀がありますが、本コラムでは以下のような⼿順で作成する⽅法を紹介します。
(1) 各被験者のテスト得点(項目得点の総和)を求めます。
(2) テスト得点をキーにして、点数の⾼い⼈から順にデータ全体をソートします。
(3) 各グループの⼈数がほぼ等しくなるように被験者全体を5等分します。
このとき低得点のグループから⾼得点のグループまでを、それぞれ「Lグループ」「LMグループ」「Mグループ」「MHグループ」「Hグループ」と呼びます。
(4) グループごとに選択肢の選択確率を計算します。
選択確率は、グループ内での各項目反応の⼈数をグループ内総数で除することによって求めます。
例えばLグループの総数が150⼈で、そのうち24⼈が項目反応1を選択していた場合は24/150 = 0.16とします。図1の場合は以下のようになっています。
(2) テスト得点をキーにして、点数の⾼い⼈から順にデータ全体をソートします。
(3) 各グループの⼈数がほぼ等しくなるように被験者全体を5等分します。
このとき低得点のグループから⾼得点のグループまでを、それぞれ「Lグループ」「LMグループ」「Mグループ」「MHグループ」「Hグループ」と呼びます。
(4) グループごとに選択肢の選択確率を計算します。
選択確率は、グループ内での各項目反応の⼈数をグループ内総数で除することによって求めます。
例えばLグループの総数が150⼈で、そのうち24⼈が項目反応1を選択していた場合は24/150 = 0.16とします。図1の場合は以下のようになっています。
(5) 横軸にグループを、縦軸に選択確率を配したグラフを⽤意し、各グループにおける各項目反応の選択確率をプロットし、直線で結びます。
被験者総数が⼤きければグループの数を増やしても折れ線グラフは安定しますし、より詳細な項目特性を考察することができます。逆に、被験者総数が⼩さければ、グループ数を増やすと各グループに配される被験者が少なくなってしまい、折れ線グラフが安定しなくなります。
この点を考慮し、慎重にグループ数を決定するようにしましょう。とはいえ、最低でもL、M、Hの3グループは必要となります。
3.項目特性図による分析
それでは実際に、項目特性図を使って各項目の善し悪しを判断してみましょう。
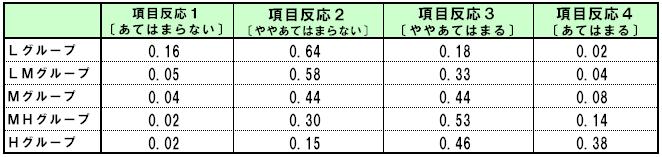
ここでは図1と同様に4件法で構成されたあるテストの結果を利⽤します。まずは図2を⾒て下さい。
ここでは図1と同様に4件法で構成されたあるテストの結果を利⽤します。まずは図2を⾒て下さい。
まず項目反応1「あてはまらない」に関してはすべてのグループで選択確率が低くほとんど機能していない、⾔い換えるとグループを識別することができないことが⾒て取れます。
しかし項目反応2「ややあてはまらない」になると低特性者(テストの総得点が低い⼈)集団のグループであるLグループやLMグループで若⼲選択確率が上がっており、また⾼特性になるにしたがって選択確率の低下が⾒られます。
つまり、このテストの得点が低い⼈は、この項目で「2」を選ぶ傾向が⾒て取れるという良い傾向を⽰しています。
この傾向は項目反応3「ややあてはまる」についても同様です。項目反応3のLグループで若⼲選択確率が低いのは、項目反応3の代わりに項目反応2を選ぶからだと考えられ、それほど問題ではありません。
⼀⽅、項目反応4「あてはまる」に関しては、被験者が⾼特性(テストの総得点が⾼い)になるにしたがって選択確率が増⼤しており、良い傾向を⽰しています。
以上のことから、この項目は「良い項目」であると判断できるでしょう。
次に注目するべきところは、識別に⼤きく関わっている項目反応3と項目反応4が交差している場所です。
図2の場合はMHグループのところで交差しています。
これは、ある程度特性が⾼くならないと(Hグループにならないと)「4」を選択しないということを意味しており、⾼特性者の識別に効⼒を発揮する項目だと考えられます。
このような項目のことを⾼特性者識別項目と呼びます。
⾼特性者識別項目を多く含んだテストを構成した場合、非常に難易度の⾼いテストになるでしょう。
項目特性図の基本的な読み⽅は上記の通りです。
注意すべきところは識別に関わる場所についてだけです。
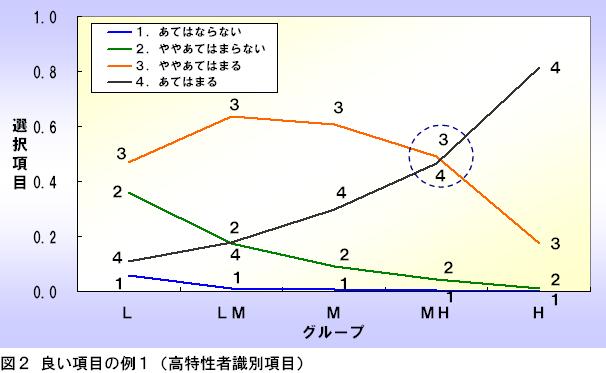
例えば、図3のような項目特性図の場合、項目反応2と3がMグループ付近で交差しています。この場合、当該特性が中程度の⼈たちを識別するのに効⼒を発揮します。
このような項目を中特性者識別項目と呼びます。
図2の場合はMHグループのところで交差しています。
これは、ある程度特性が⾼くならないと(Hグループにならないと)「4」を選択しないということを意味しており、⾼特性者の識別に効⼒を発揮する項目だと考えられます。
このような項目のことを⾼特性者識別項目と呼びます。
⾼特性者識別項目を多く含んだテストを構成した場合、非常に難易度の⾼いテストになるでしょう。
項目特性図の基本的な読み⽅は上記の通りです。
注意すべきところは識別に関わる場所についてだけです。
例えば、図3のような項目特性図の場合、項目反応2と3がMグループ付近で交差しています。この場合、当該特性が中程度の⼈たちを識別するのに効⼒を発揮します。
このような項目を中特性者識別項目と呼びます。
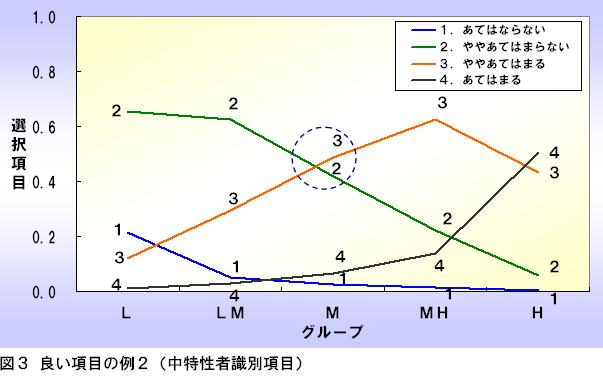
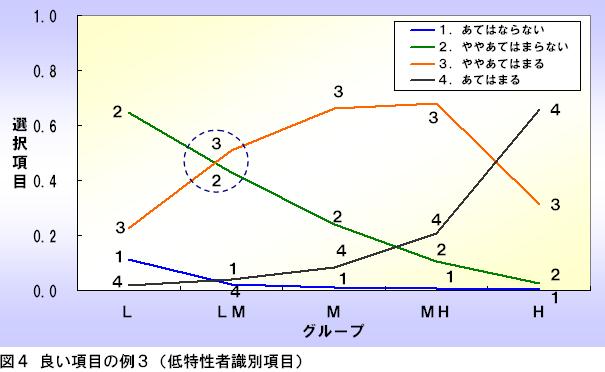
⼀⽅、図4の場合、項目反応2と3がLMグループのところで交差していますので、この項目は低特性者の識別に貢献しています。このような項目は低特性者識別項目と呼びます。
図2~図4までのような、3種類の項目をバランス良く含めたテストを作成することで、特性の低い⼈から⾼い⼈までを広範囲に識別できるテストを作成することが可能です。
また、⾼特性者識別項目を多めに含めた場合は⾼得点を取るのが難しめなテストに、低特性者識別項目を多めに含めた場合は⾼得点を取りやすい易しめなテストに操作することが可能です。テストの目的によって使い分けるとよいでしょう。
図2~図4までのような、3種類の項目をバランス良く含めたテストを作成することで、特性の低い⼈から⾼い⼈までを広範囲に識別できるテストを作成することが可能です。
また、⾼特性者識別項目を多めに含めた場合は⾼得点を取るのが難しめなテストに、低特性者識別項目を多めに含めた場合は⾼得点を取りやすい易しめなテストに操作することが可能です。テストの目的によって使い分けるとよいでしょう。
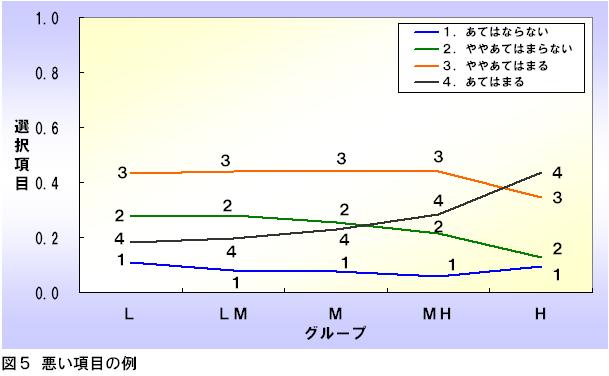
⼀⽅、図5のような項目特性図を描く項目は「悪い項目」です。
なぜなら、すべてのグループにわたってそれぞれの項目反応が平⾏になっているからです。項目反応4に関しては、特性の上昇に伴い、多少は増⼤していますが、その変化はそれほど⼤きくはありません。
つまりこの項目は特性の⾼さによらず、ランダムに1〜4が選択されるということです。これではどの項目反応からも特性の⾼さを識別することはできません。
このような項目はテストから削除し、次回以降は使⽤しないようにするのが良いでしょう。
なぜなら、すべてのグループにわたってそれぞれの項目反応が平⾏になっているからです。項目反応4に関しては、特性の上昇に伴い、多少は増⼤していますが、その変化はそれほど⼤きくはありません。
つまりこの項目は特性の⾼さによらず、ランダムに1〜4が選択されるということです。これではどの項目反応からも特性の⾼さを識別することはできません。
このような項目はテストから削除し、次回以降は使⽤しないようにするのが良いでしょう。
4.通過率
ここでは、先ほどの4件法のデータに関して、さらに情報の圧縮を⾏います。項目反応1と2を「0」に、項目反応3と4を「1」に再⼊⼒します。
すると以下のようなデータが構成されることになります。
すると以下のようなデータが構成されることになります。

このような形式のデータのことを2値反応データ(binary response data)といいます。
(ただし、明確な正答と誤答が存在する多肢選択問題の場合は正答を1、誤答を0に再⼊⼒しま
す。)
(ただし、明確な正答と誤答が存在する多肢選択問題の場合は正答を1、誤答を0に再⼊⼒しま
す。)
この2値反応データから「通過率」と呼ばれる指標を計算してみましょう。
通過率は別名、正答率とも呼ばれます。
この指標は、テストを構成する個々の項目の性質を調べるためのものです。
計算⽅法は⾄って簡単で、項目ごとに「1」と反応した⼈の数を被験者総数で除することによって求めます。
通過率は別名、正答率とも呼ばれます。
この指標は、テストを構成する個々の項目の性質を調べるためのものです。
計算⽅法は⾄って簡単で、項目ごとに「1」と反応した⼈の数を被験者総数で除することによって求めます。

つまり通過率は、各項目に正答した被験者の割合として解釈することが可能です。
(テスト理論では性格検査などでも、「1」と反応することを「正答する」と表現することがあります)
通過率は、0と1の間の数字をとり、値が⼤きな項目ほど(正解した⼈が多いので)易しい項目であると解釈します。これらの値は、先ほど紹介した項目特性図と合わせて考察することで、その項目が良い項目なのか、そうではないのかを判断する材料になります。
(テスト理論では性格検査などでも、「1」と反応することを「正答する」と表現することがあります)
通過率は、0と1の間の数字をとり、値が⼤きな項目ほど(正解した⼈が多いので)易しい項目であると解釈します。これらの値は、先ほど紹介した項目特性図と合わせて考察することで、その項目が良い項目なのか、そうではないのかを判断する材料になります。
5.識別⼒
しかし、2値反応データの場合、標準偏差を計算して項目分析に使⽤することはほとんどありません。その代わりに「識別⼒」と呼ばれる指標を計算します。
識別⼒とは、各項目得点とテスト得点の相関係数のことです。
したがって、識別⼒の⾼い項目は、項目得点がテスト全体で測定している特性を適切に反映し、被験者を区別している項目であると解釈します。逆に、識別⼒の低い項目は、項目得点が特性を適切に反映していない項目であると考えられます。
識別⼒は、最⼤値が1であり、1に近いほど識別⼒が⾼く、0に近いほど識別⼒が低いと判断します。識別⼒は相関係数のことですので、原理的には負の値になることも考えられます。
例えば、逆転項目(※1)などは負の値になります。しかし、このような項目はあらかじめ反転させておくので、負の値が登場することはほとんどありません。正解と不正解がある学⼒テストのような場合も、テスト得点が⾼くなるほど不正解になるような項目は珍しいので、実質的に識別⼒が負になることは滅多にないでしょう。
識別⼒を考える場合に注意すべき点が1つあります。
それは、テスト得点は各項目得点の和で計算されており、テスト得点の中に当該項目得点が含まれてしまっていることです。そのため項目数が少ない場合は、相関係数である識別⼒は⼤きくなる傾向にあります。
対処法としては、当該項目を除いた場合の残りの項目合計得点をテスト得点とし、それと当該項目との相関係数をその項目の識別⼒として利⽤することです。この指標も項目特性図と合わせて解釈することで、項目分析に効果を発揮するでしょう。
※1 逆転項目:「当てはまる」と回答するとネガティブな意味になるような項目こと。 例えば、チャレンジする意欲があるかどうかを尋ねる場合で、「私は新しいことに挑戦したくない」のような項目のこと。
6.項目分析の活⽤
さて、項目分析は実際にどのように活⽤することになるでしょうか。
社内の昇格試験など、不合格者などがいて2年連続して受験する⼈がいる場合、今年度の問題項目と来年度の問題項目を変えることがよくあります。これは毎年繰り返されることになるでしょう。
しかし、ある程度の年数が⽴つと、項目数も豊富になるので、過去のいくつかの項目を組み合わせて新たなテストが作成できるようになります。このようなとき、「悪い項目」はできる限り使わないようにするのが望ましいです。
そこで、毎年の試験後に項目分析を実施しておき、「良い項目」は残し、「悪い項目」は削除するようにします。そうすることによって「良い項目」のみが確保でき(このような項目群のことを項目プールと呼びます)、将来にわたって良質なテストが作成できるようになるのです。
次回は、作成したテストの「信頼性」と「妥当性」を調べる⽅法について解説します。
(担当 : 経営管理研究所 福中 公輔)