【第3回】⼈材開発活動に必要なアンケート調査の考え⽅・すすめ⽅
テーマ:集計に関する基本的な知識
(誌上セミナー担当:堀内 勝夫 総合研究所)
1.度数分布表の作成
データの⼊⼒が終了したら、まず各変数(質問項目)について単純集計を⾏います。
具体的には、度数分布表を作成し、回答の分布を検討します。
度数分布表とは、測定値ごとの度数もしくは相対度数(割合)を記⼊した集計表です。
度数(frequency)とは、各測定値の出現個数のことを意味します。
度数分布の検討は、全ての変数について最初に⾏います。
具体的には、度数分布表を作成し、回答の分布を検討します。
度数分布表とは、測定値ごとの度数もしくは相対度数(割合)を記⼊した集計表です。
度数(frequency)とは、各測定値の出現個数のことを意味します。
度数分布の検討は、全ての変数について最初に⾏います。
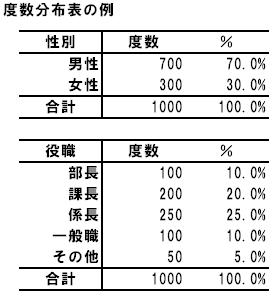
上の例で⽰しているように、 各値(カテゴリー)の回答者数(度数)を集計し、⽐率を算出します。
そして端に度数の合計と、割合の合計を載せましょう。⽐率を提⽰する場合は、⼀般的に⼩数点第1位までの値を記述します。
そして端に度数の合計と、割合の合計を載せましょう。⽐率を提⽰する場合は、⼀般的に⼩数点第1位までの値を記述します。
2.単純集計のグラフ化
データの集計や分析とは、膨⼤なデータを⼈間が理解できる範囲のものに変換する作業であると⾔えます。
グラフ作成もその⼀連の流れとして考えられます。報告書として調査結果を提⽰する場合には、多くはグラフが⽤いられます。グラフの利点は、情報を視覚的に捉えやすいということです。つまりグラフの役割は、データを視覚的に把握しやすいように整理することと⾔えます。
度数分布表をグラフ化したものをヒストグラム(histogram)といいます。度数分布表よりも、データの分布の形が直感的に分かるという利点があります。
ヒストグラム作成の際には、横軸に測定値、縦軸に度数をとります。
グラフ作成もその⼀連の流れとして考えられます。報告書として調査結果を提⽰する場合には、多くはグラフが⽤いられます。グラフの利点は、情報を視覚的に捉えやすいということです。つまりグラフの役割は、データを視覚的に把握しやすいように整理することと⾔えます。
度数分布表をグラフ化したものをヒストグラム(histogram)といいます。度数分布表よりも、データの分布の形が直感的に分かるという利点があります。
ヒストグラム作成の際には、横軸に測定値、縦軸に度数をとります。
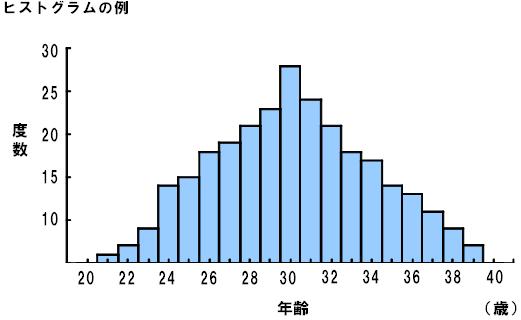
度数分布表、あるいはヒストグラムを作成することによって、以下の点を読みとることができます。
(1)⼊⼒ミスの有無
例えば、性別という変数に対して、男性を「0」、⼥性を「1」とコード化して⼊⼒したにも関わらず、度数分布表にそれ以外の数字が⼊っていれば、それは⼊⼒ミスによるものであると考えられます。
(2)極端値の有無
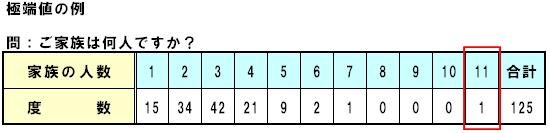
極端値とは、データ全体の分布から⼤きく外れて、孤⽴しているような値のことです。
例えば、下の表において、「11」は極端値です。なぜなら、データ全体は1~4に集中しているが、「11」は他と⼤きく離れて、単独で分布しています。
本来なら極端値がある場合、データに対してそれ以上の統計的処理を⾏うことは望ましくありません。しかし、その極端値が出た原因を個別に追求し、不良値であるとわかったらそれを除外して分析を進めることができます。
例えば、下の表において、「11」は極端値です。なぜなら、データ全体は1~4に集中しているが、「11」は他と⼤きく離れて、単独で分布しています。
本来なら極端値がある場合、データに対してそれ以上の統計的処理を⾏うことは望ましくありません。しかし、その極端値が出た原因を個別に追求し、不良値であるとわかったらそれを除外して分析を進めることができます。
(3)標本の構成
(4)回答の分布
度数分布を確認することによって、どのくらいの⼈数がどのような回答をしているのかを把握することができます。これが度数分布表の本来の役割です。
回答の分布については以下の点を検討しましょう。
回答の分布については以下の点を検討しましょう。
- 各選択肢がどの位の割合で選ばれているのか。均等に選ばれているのか、どこかに偏っていないか。
- ほとんど選ばれていないような選択肢がないか。
- 評定形式の選択回答形式であり、さらに「普通」や「どちらともいえない」等の中間の選択肢がある場合は、それら中間選択肢に回答が集中してしまっていないか。中間の選択肢に回答が集中してしまっていると、後の分析を⾏いにくくなる。
- 評定形式の選択回答形式の場合は、「良い」や「賛成」等の肯定的評価に回答した傾向と、反対に否定的な⽅向に回答した傾向の割合を調べる。
- 順位づけの回答⽅法の場合に、1位と多くの⼈に判断された選択肢はどれか。
- 順位づけの回答⽅法の場合に、順位づけに何らかの特徴は⾒られないか。
3.記述統計量の算出
⼀般には「代表値」と「散布度」がその指標となり、このような統計指標を「記述統計量」と呼びます。⾔い換えれば、記述統計量を⽤いることによってデータの分布情報を要約することになります。
代表値と散布度にはいくつかの種類があり、尺度の⽔準や変数の種類によって適⽤できるものに制限があります。その点についても随時確認しながら解説していきます。
4.代表値
ここでいう"代表"とは、それを知ればデータの全体的傾向についておおよそ知ることができるというような、"典型的、⼀般的なもの"という意味です。
代表値には最頻値、中央値、平均値の3つがあり、測定に⽤いられた尺度の⽔準(第2回を参照してください。)や実際に観測されたデータの分布などを考慮して最も適切なものを選ぶことになります。
(1)最頻値(Mode:Mo)
度数が最も多い測定値(ないしカテゴリー)を指し、モードとか並み数と呼ばれることもあります。
最頻値は名義尺度・順序尺度・間隔尺度・⽐例尺度のどの⽔準のデータに対しても適⽤することができます。
例えば、100⼈の⼈に対して下のような質問を⾏い、その結果が得られたとする。この場合、最頻値は最も度数の多い「1」、すなわち「A型」です。ここで、最頻値は「35」ではないことに注意しましょう。
最頻値は名義尺度・順序尺度・間隔尺度・⽐例尺度のどの⽔準のデータに対しても適⽤することができます。
例えば、100⼈の⼈に対して下のような質問を⾏い、その結果が得られたとする。この場合、最頻値は最も度数の多い「1」、すなわち「A型」です。ここで、最頻値は「35」ではないことに注意しましょう。

(2)中央値(Median:Me)
データの⽔準が順序尺度・間隔尺度・⽐例尺度である場合に適⽤できる代表値です。データを⼤きさの順に並べたときにちょうど中央に位置する値であり、ヒストグラムの⾯積を2等分する値ともいえます。
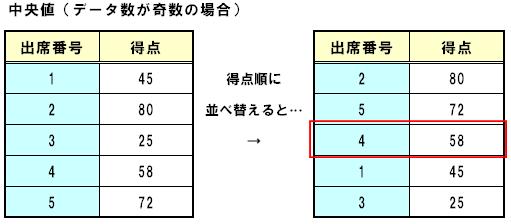
データ数(n)が奇数のときには、「(n+1)/2」番目の測定値を中央値とします。
例えば、下の例のような5⼈のテストの得点があった場合、(5+1)/2=3であるから、3番目に⾼い得点である58が中央値となります。
データ数(n)が奇数のときには、「(n+1)/2」番目の測定値を中央値とします。
例えば、下の例のような5⼈のテストの得点があった場合、(5+1)/2=3であるから、3番目に⾼い得点である58が中央値となります。
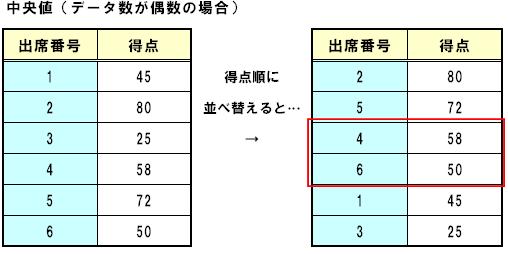
データ数が偶数のときには、「n/2」番目の測定値と、「(n/2)+1」番目の測定値の間に中央値が存在することになりますが、それら2つの測定値を⾜して2で割った値を中央値とすることが多いようです。
例えば、下の例のような6⼈のテストの得点があった場合、(6/2)=3番目に⾼い得点(58)と、(6/2+1)=4番目に⾼い得点(50)の平均をとって、54が中央値となります。
例えば、下の例のような6⼈のテストの得点があった場合、(6/2)=3番目に⾼い得点(58)と、(6/2+1)=4番目に⾼い得点(50)の平均をとって、54が中央値となります。
(3)平均値(mean)
データの⽔準が間隔尺度または⽐例尺度である場合に適⽤される代表値です。ここでは最も⼀般的で使われる頻度の⾼い、算術平均について解説します。
算術平均は「相加平均」とも呼ばれ、⼀般に、―X(エックスバー)、またはMと表記されます。
データの総和(ΣXi)をデータ数(n)で割ることにより算出されます。
算術平均は「相加平均」とも呼ばれ、⼀般に、―X(エックスバー)、またはMと表記されます。
データの総和(ΣXi)をデータ数(n)で割ることにより算出されます。
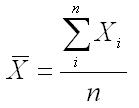
例えば、10⼈のテストの得点が、下の例のようであったとすると、

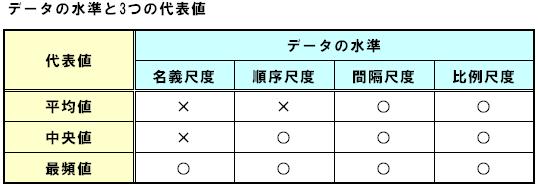
(4)3つの代表値の⽐較
それぞれの代表値を⽤いることができる尺度の⽔準を⽰したものです。
データの⽔準が間隔尺度あるいは⽐例尺度である場合には、3つの代表値のいずれも適⽤可能です。
データの⽔準が間隔尺度あるいは⽐例尺度である場合には、3つの代表値のいずれも適⽤可能です。
※尺度については、第2回「 2-4.回答形式の決定」を参照ください。
5.散布度
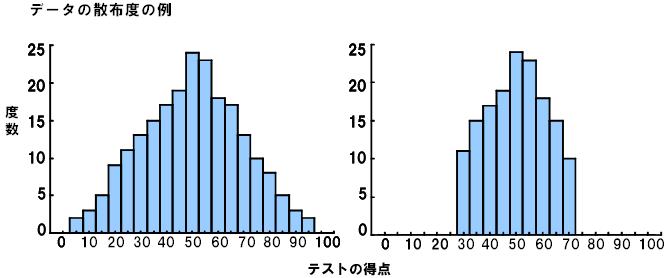
下図の2つのヒストグラムは、両⽅とも平均値が50となるように作られたグラフですが、明らかに分布は異なっています。つまり、代表値だけでデータの特徴がすべて表されるわけではありません。
代表値が等しくても、データのばらつきの程度が異なれば、それらのデータは異なるものとみなされます。このばらつきの程度を「散布度」といいます。
例えば、散布度が⼩さいほど、「50」という平均値がデータ全体の傾向を表している程度が⼤きいことがわかります。すなわち、散布度は代表値の信頼性を⽰すと⾔えます。
代表値が等しくても、データのばらつきの程度が異なれば、それらのデータは異なるものとみなされます。このばらつきの程度を「散布度」といいます。
例えば、散布度が⼩さいほど、「50」という平均値がデータ全体の傾向を表している程度が⼤きいことがわかります。すなわち、散布度は代表値の信頼性を⽰すと⾔えます。
散布度には、レンジ、分散、標準偏差などがありますが、これらはどの代表値を選択したかによって適⽤できるものが限定されます。
(1)レンジ(range:R)
レンジは、代表値が中央値である場合に⽤いる散布度の測度であり、データの最⼤値と最⼩値の差として定義されます。レンジが⼤きいほど、散布度は⼤きいとみなされます。
例えば、下の表のような5⼈のテストの得点があった場合、中央値は58、レンジは(80-25)で55となります。
例えば、下の表のような5⼈のテストの得点があった場合、中央値は58、レンジは(80-25)で55となります。
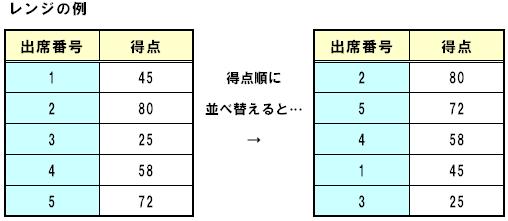
しかし、レンジはデータ数が多いほど⼤きくなる確率が⾼いという⽋点があります。データ数が多いほど、それらのデータの中に極端に⼤きい、または⼩さい値が含まれている確率が⾼くなるからです。
(2)分散(variance:S2)
分散は、代表値が平均値である場合に⽤いる散布度の測度であり、以下の式によって定義されます。
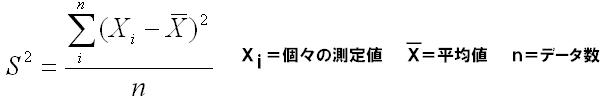
この式からもわかるように、分散とは「個々の測定値の平均値からのズレ(偏差と⾔います)を2乗したものの和を、データ1個分に換算した」値です。
2乗しているのは、ズレの+・-を消すための処置です(偏差を合計すると0になってしまうため)。
分散が⼤きいほど、散布度は⼤きいと解釈できます。
また、分散が⼩さいということは、平均値のすぐ近くにデータが集中していることを意味します。
2乗しているのは、ズレの+・-を消すための処置です(偏差を合計すると0になってしまうため)。
分散が⼤きいほど、散布度は⼤きいと解釈できます。
また、分散が⼩さいということは、平均値のすぐ近くにデータが集中していることを意味します。
(3)標準偏差(standard deviation:SまたはSD)
標準偏差は、代表値が平均値である場合に⽤いる散布度の測度であり、分散の平⽅根をとったものです。
分散を算出したときに、偏差を2乗したため、元のデータの単位と異なってしまっています。
例えば、⻑さを表す1mを2乗すると⾯積を表す1㎡(平⽅メートル)になります。1mと1㎡は⽐べられません。それを元の単位に戻すために平⽅根をとることで、代表値の単位と揃えることができます。
分散を算出したときに、偏差を2乗したため、元のデータの単位と異なってしまっています。
例えば、⻑さを表す1mを2乗すると⾯積を表す1㎡(平⽅メートル)になります。1mと1㎡は⽐べられません。それを元の単位に戻すために平⽅根をとることで、代表値の単位と揃えることができます。
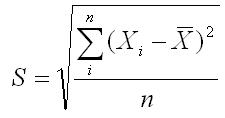
単純集計と記述統計量の算出は、得られたデータを解釈、分析するために⽋かせない作業となります。これらの結果をよく読み込んでいくことがデータ分析の最初の⼀歩です。
アンケート調査の結果報告に代表値しか表⽰していないものをよく⾒かけます。代表値だけではそのデータの⼀部分しか⾒えてきません。どのような場合でもデータがどのように分布しているかを意識することが非常に⼤切です。
アンケート調査の結果報告に代表値しか表⽰していないものをよく⾒かけます。代表値だけではそのデータの⼀部分しか⾒えてきません。どのような場合でもデータがどのように分布しているかを意識することが非常に⼤切です。
おわりに
当⽇、混乱はあったものの、幸いなことに、ご参加いただいた⽅々には怪我もなく、とにかく定刻まで実施させていただきました。しかし、内容的には半分ほどしか説明することができませんでしたので、ポイントだけになりますが、改めてここに掲載させていただいた次第であります。
3回にわたる⻑⽂のコラムをお読みいただき、ありがとうございました。このコラムが皆様にとって何らかのお役に⽴つようでしたら、筆者にとって望外の喜びです。
2011年8⽉
堀内 勝夫
参考⽂献
・ウソを⾒破る統計学 神永 正博著 講談社 ブルーバックス 2011
・社会調査法⼊門 盛⼭ 和夫著 有斐閣 2004
・新・涙なしの統計学 D. ロウントリー著 新世社 新版 2001
・組織調査ガイドブック―調査党宣⾔ ⽥尾 雅夫 (編集), 若林 直樹 (編集) 有斐閣 2002