人事業務におけるクラスター分析の活用(1)

はじめに
近年のテクノロジーの進化に伴い、人事×データサイエンス=HR Techへの注目が集まっている中、人事担当者にとってもデータサイエンスの基礎知識を理解し、データ活用リテラシーを向上する必要性が高まっている。
今回のコラムでは、(2018年12月掲載)
に引き続き、データマイニング手法の一つである「クラスター分析」を取り上げる。
データマイニング手法によってできることは主に下記の3つに集約される。
「規則の発見」 「分類・判別」 「関係性の探索」
今回紹介するクラスター分析は、「分類・判別」によって意思決定を支援するデータマイニング手法の一つであり、人事業務における採用時の人材の見極めや、人材活用における意思決定を行う際の判断を支援する方法として有効である。
コラムの第1回目は、クラスター分析の概要を、第2回目はクラスター分析を用いた分析事例と人事業務におけるクラスター分析の活用可能性について述べていきたい。
教師あり学習と教師なし学習
データマイニングはコンピューターにデータを与えて学習させることで規則や分類を得ようとするが、コンピューターに学習させる方法には「教師あり学習」と「教師なし学習」がある。
教師あり学習とは
「教師あり学習」とは、インプットデータとアウトプットデータをセットでコンピューターに提示して学習させ、両者の間の規則性を導き出そうとするものである。
例えば「部下の残業を減らしたい」という目的の下、「部下の残業の有無」というアウトプットデータに対して、「抱えている案件の数」や「社員の能力」等のインプットデータを用意して、アウトプットとインプットの間にある規則性を見いだそうとするものである。
教師なし学習とは
一方の「教師なし学習」は、インプットデータのみでコンピューターに特定のアルゴリズムを用いた学習をさせ、判断に役立つ基準を作らせようとする方法である。
「教師なし学習」は「教師あり学習」とは異なり、インプットとアウトプットの明確な対応関係を想定せずに実施することができるため、分析者が気づいていない新たな分類基準等の発見が期待できる。
クラスター分析は「教師なし学習」により、データから意思決定のための分類・判別を行う基準を定量的に示そうとする方法である。
クラスター分析とは
1.クラスター分析が使われる場面
そもそも「クラスター(cluster)」とは、「集団」や「群れ」を意味する言葉である。
さまざまな性質を持ったデータを、似た性質のデータ同士で集めてグループ化・分類する(クラスターに分ける)ことが、クラスター分析という手法の基本的な考え方である。
われわれの身近なところでクラスター分析が使われている例の一つに、企業から届くダイレクトメール等の販促活動がある。
企業は、ダイレクトメールをどんな顧客に送付すれば効果的な販促活動ができるかを検討し、ダイレクトメールの内容や送付先を絞り込む。
こうした検討や絞り込み作業にクラスター分析を用いている企業は数多くある。
年齢、性別、年収、購買履歴などのさまざまな属性情報を持つ顧客データを用いてクラスター分析を行い、「よくある顧客のタイプ」を明らかにする。「年収が高い中高年男性」「インターネットで購買する頻度が高い30代女性」「店頭で購買する頻度が高い50代女性」のように、顧客のタイプを明確に分類し、それぞれのタイプに合わせた効果的な販促活動を検討してプロモーションを行うのである(図表1)。
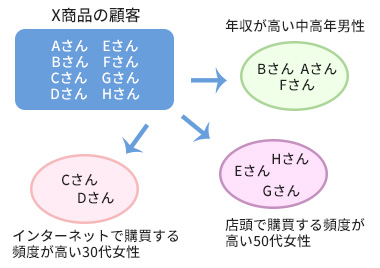
上記のようなマーケティングの領域では、顧客へのアプローチ方法を検討するために、“顧客”を分類するが、人事業務では社員の採用や異動等の際に人材を見極める目的で、“社員”を分類する方法として用いられている。
クラスター分析によって、これまで経験的に捉えていた社員のタイプを確認できるとともに、これまで気づかなかった新しい社員のタイプを発見することも期待できる。
2.クラスター分析が行う“分類”とは
世の中の意思決定はすべて“分類”が土台になっていると言っても過言ではない。
複数の選択肢からの選択、特定の出来事に対する良い・悪いの判断などの意思決定には、判断のための基準が必要となる。
そして、その基準は多くの類似の事例や概念的な考え方などの情報を分類することで作られる。
われわれが意思決定を困難に感じる場合の多くは、知識・経験が不足している時である。
これは「目の前に起きた事象が自分の持つ分類基準にうまく当てはまらない」から困難に感じるのである。
これまでに経験したことのない出来事が起きた場合に、あるべき判断基準を知らないがゆえに誤った意思決定をしてしまうこともある。
人の意思決定は、経験的に蓄積された知識・経験だけで行うには限界があるといえよう。
さらに、知識・経験を備えていたとしても、分類する対象があまりにも膨大になると人間の頭だけでは判断しきれない。
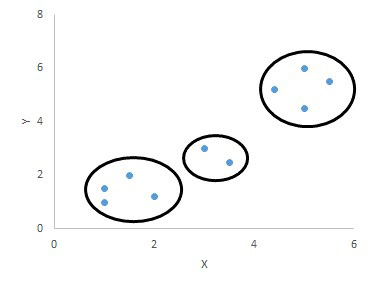
例えば、図表2の〔データ1〕を分類しようとすると、感覚的に図表3のように3つに分類できるが、図表2の〔データ2〕の場合は感覚的に分類するのが困難である。
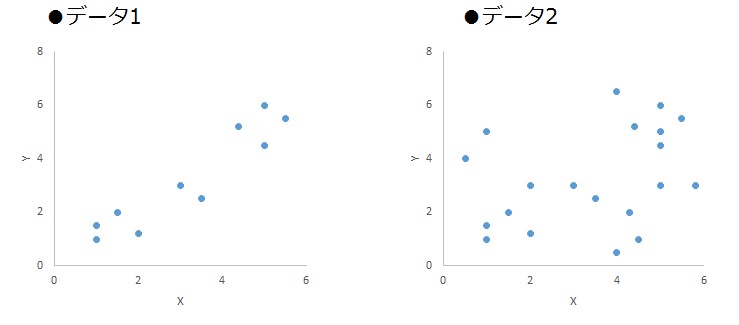
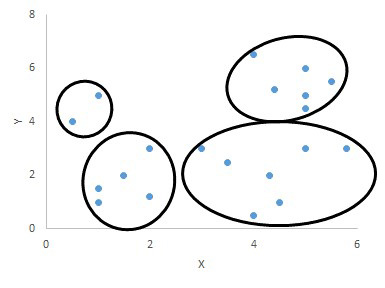
〔データ2〕のようにデータ量が多く、散らばりの度合いが大きくなると、データを何個に分類するか、どのようなくくりでデータを分類するか、さまざまなパターンが考えられる。
そこで、〔データ2〕をクラスター分析で分類すると、定量的な計算結果に基づき図表4のような分類結果を導くことができる。クラスター分析はデータを基に、分類を探し出す支援をしてくれるのである。(次号に続く)